1. 硬件与安装
1.1. Intel NUC11 与 proxmox
Intel NUC 11 低功耗,安静,体积比 Mac mini 还小,硬件强大,配上 16G 内存,一块 120G 的普通 SSD 作为 proxmox 的安装盘,一块 1T nvme 接口 的 SSD 作为数据盘,可以满足大部分的需求。
使用 proxmox 作为虚拟化管理软件,可以方便地创建系统级容器(LXC)
1.2. 安装 PVE
https://pve.proxmox.com/wiki/Prepare_Installation_Media#_instructions_for_windows
使用 Etcher 烧录 ISO 文件至 USB 盘,插入目标主机,开机进入 BIOS 编辑引导盘从 USB 盘开始,安装 PVE
2. PVE 使用
使用 PVE 创建虚拟机或 LXC
2.1. 安装 Openwrt 作为旁路由
- IMG 镜像文件来源https://github.com/ApertureG/OpenWrt/releases
PVE 安装 Openwrt 设置 https://felixqu.com/2021/09/05/setup-openwrt-on-pve/
注意复制上传的镜像文件路径以及创建虚拟机之后编辑引导顺序
2.1.1. 设置 Openclash
Openwrt 镜像中已经安装了 openclash,登录 Openwrt 在服务中找到 openclash
配置文件管理,可以先手动上传一份配置文件,再设置配置文件订阅
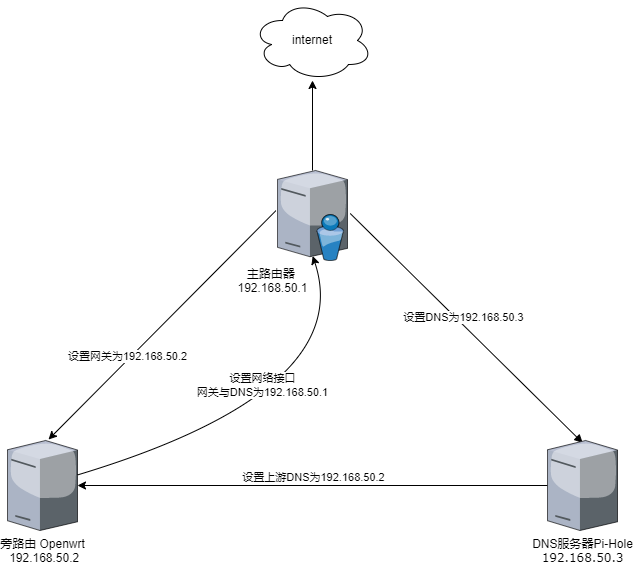
2.2. 设置旁路由
2.2.1. 修改 Openwrt 设置
登录 openwrt
网络 -> 接口 LAN -> 修改
一般配置 -> 基本配置 -> IPv4 网关: 填写主路由 IP
-> IPv4 广播: 设置为主路由网段,最后一位为 255
-> 使用自定义的 DNS 服务器: 填写主路由 IP
-> 物理设置 -> 桥接接口: 取消勾选
-> 接口: 选择对应的硬件 LAN 接口
DHCP 服务器 -> IPv6 设置 -> DHCPv6 服务: 修改为已禁用
保存&应用
2.2.2. 修改主路由设置
登录主路由
内部网络(LAN) -> DHCP 服务器 -> 基本设置 -> 默认网关: 填写为 Openwrt 的 IP
-> DNS 服务器设置: 填写为 Openwrt 的 IP
这样的设置为主路由不关闭 DHCP 服务器,只设置 DHCP 的默认网关
保存&应用
2.2.3. windows 机器设置 chrome 浏览器
设置后发现接入家用网络的 windows 机器出现以下现象
- github 无法访问
- youtube 可以访问,但是无法播放视频
解决方法
chrome://settings 搜索 dns security -> Advanced -> Use secure DNS 选择 With Cloudflare 1.1.1.1
2.4. HomeAssistant
安装 HomeAssistant 将小米设备接入 Apple HomeKit,通过 Siri 控制家族智能设备
following the instruction of https://www.youtube.com/watch?v=tZflVxBq6Sw
HomeAssistant 虚拟机启动报错问题:
in the Proxmox VM. When you see the Proxmox logo when booting a VM, hit escape and then go to Device Manager -> Secure Boot Configuration then disable Attempt Secure Boot.
2.5. aliyundrive-webdav
将阿里云盘作为文件夹挂载到 windows 电脑中
2.6. Samba
设置 Sambda 服务器,用于局域网共享文件夹
将 1T 的 SSD 格式化之后挂载到 PVE. 挂载路径 /mnt/data
创建用于共享的文件夹 /mnt/data/share
PVE 创建 Ubuntu LXC ,创建后不启动,如 LXC ID 为 104
在 PVE 上编辑配置文件 /etc/pve/lxc/104.conf 加入 bind mount ,将共享文件夹挂载到容器内的 /mnt/share 路径
mp0: /mnt/data/share,mp=/mnt/share
启动容器,安装 Samba
apt update && apt upgrade -y apt install net-tools #Needed for ifconfig, etc. apt install samba # 新建用户 adduser --system smbusr # 设置密码 smbpasswd -a smbusr
编辑文件 /etc/samba/smb.conf 加入
[Share]
comment = Share
path = /mnt/share
read only = no
writeable = yes
browsable = yes
force user = smbusr
service smbd restart ufw allow samba
